指针与数组、函数
本文共 2078 字,大约阅读时间需要 6 分钟。
《c primer plus 》阅读笔记
一、指针表示法和数组表示法: 1.指针表示法和数组表示法优缺 使用数组表示法,让函数是处理数组的这一意图更加明显。另外,许多其他语言的程序员对数组表示法更熟悉,如FORTRAN、Pascal、Modula-2或BASIC。其他程序员可能更习惯使用指针表示法,觉得使用指针更自然。 至于C语言,ar[i]和*(ar+1)这两个表达式是等价的。无论ar是数组名还是指针变量,这两个表达式都没有问题。但是,只有当ar是指针变量时,才能使用ar++这样的表达式。 指针表示法(尤其与递增运算符一起使用时)更接近机器语言,因此一些编译器在编译是、时能生成效率更高的代码。然而,许多程序员认为他们的主要任务是确保代码正确、逻辑清晰,而代码优化应该留给编译器去做。(以上内容《c primer plus》原文(p294))2.用指针表示法表示一维数组:
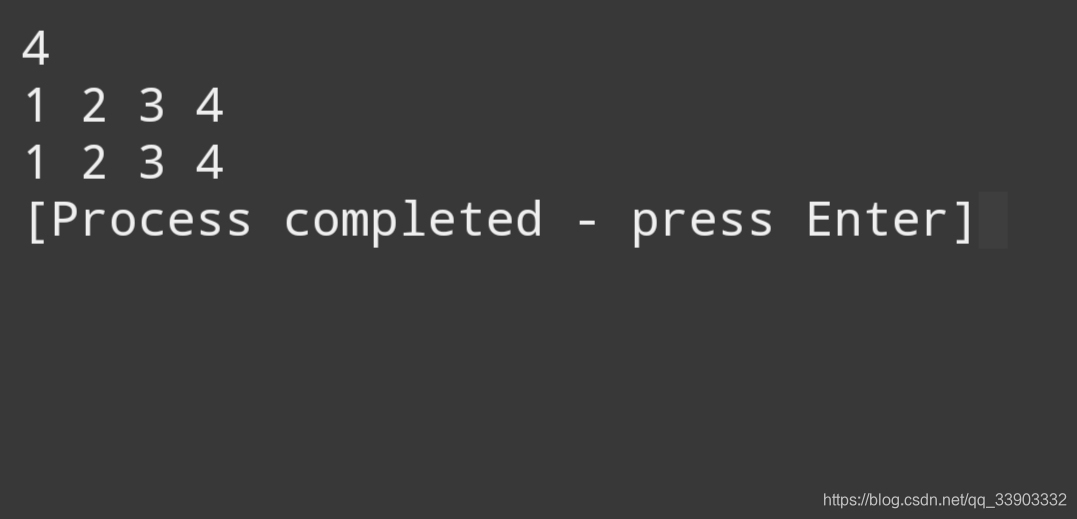
int * p; 声明了一个指向int类型的指针,其实他与声明了一个数组内似。 可以使用 * (p+i)=count(指针加1表示增加一个存储单元)对地址上存储的数据进行赋值。使用*(p+i)和使用a[i]的效果等同。 用指针表示法表示数组时,指针加1表示系统给他多分配一个存储单元,他可以多存储一个数据。而数组本身则是先分配存储空间,然后在相应的地址上存储数据(不包括变长数组和动态分配,可以说,使用指针表示数组在一定程度上达到了前者的功能) 下面看一看使用指针表示法的例子:#includeint main(void){ int *p,i,n; scanf("%d\n",&n); for(i=0;i
输出如下:
 2.声明一维数组形参 int sum(int *ar,int n)//传递给改函数一个地址和一个变量 int sum(int ar[],int n)//传递给该函数一个数组首地址(数组名)和一个变量 3.使用指针形参 指针的第一个基本用法是在函数间传递信息。如果希望在被调函数中改变主调函数的变量,就必须使用指针。指针的第二个基本用法是用在处理数组的函数中。 int sum(int *str,int *end)//可以分别传递一个数组的开始处地址和结束处地址。 二.指针和二(多)维数组
2.声明一维数组形参 int sum(int *ar,int n)//传递给改函数一个地址和一个变量 int sum(int ar[],int n)//传递给该函数一个数组首地址(数组名)和一个变量 3.使用指针形参 指针的第一个基本用法是在函数间传递信息。如果希望在被调函数中改变主调函数的变量,就必须使用指针。指针的第二个基本用法是用在处理数组的函数中。 int sum(int *str,int *end)//可以分别传递一个数组的开始处地址和结束处地址。 二.指针和二(多)维数组 - 先介绍二维数组: int a[3][4]; 二维数组既数组的数组,主数组有3个元素,每个元素是内含4个元素的数组。 a是数组首元素的地址,所以a的值和&a[0]相同,而a[0]本身是一个内含四个int类型值的数组的首地址,所以a[0]的值和&a[0][0]相同:
#includeint main(void){ int a[3][4]; printf("%p\n%p\n%p",a,a[0],&a[0[0]);}
输出如下:
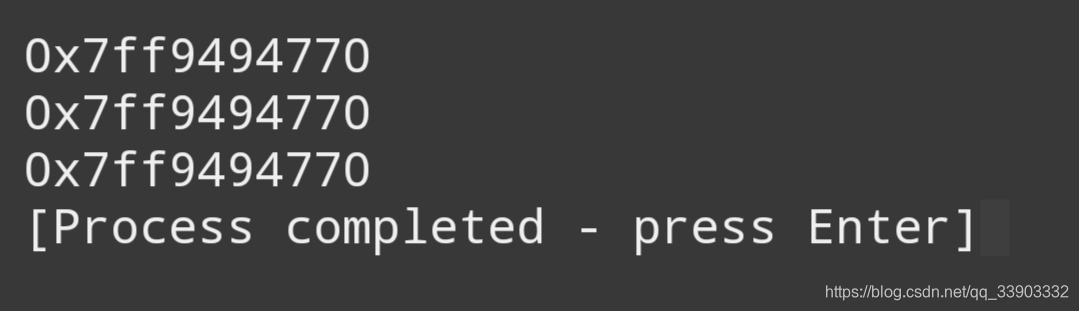 这一点体现了指针的复杂性,要记住a是地址的地址,必须解引用两次才能获得原始值。地址的地址或指针的指针就是双重间接的例子。 a[1][1]等价的指针表示法是* (* (a+1)+1),下面列出理解该表达试的思路:
这一点体现了指针的复杂性,要记住a是地址的地址,必须解引用两次才能获得原始值。地址的地址或指针的指针就是双重间接的例子。 a[1][1]等价的指针表示法是* (* (a+1)+1),下面列出理解该表达试的思路: a//二维数组首元素的地址(每个元素都是内含四个int类型元素的一维数组)
a+1//二维数组第2个元素(既一维数组)的地址
*(a+1)//二维数组的第2个元素(既一维数组)的首元素(一个int类型的值)地址
*(a+1)+1//二维数组的第2个元素(既一维数组)的第二个元素(也是一个int类型的值)地址
*( * (a+1)+1)//二维数组的第2个元素(既一维数组)的第2个元素的值
注意 * a+1和 * ( * a+1)的意义,前者中*a表示a的第二个元素(一个二维数组)首地址,加1表示第二个元素的第二个元素的地址(一个int类型的值)其他的解引用方式应该举一反三。
2.使用指针的指针(二级指针)表示二维数组
二级指针:如果一个指针指向的是另外一个指针,我们就称它为二级指针,或者指向指针的指针。注意:二级指针和二维数组本身关系不大 。int **a; a=(int**)malloc(sizeof(int*)*m); for(i=0;i
创建了一个m*n的二维数组,与a[m][n]等效。3.声明指向二维数组的指针
int a[3][4]; int (*b)[4]; b=a; 为什么是int (*b)[4]而不是int *b? 因为把指针声明为指向int的类型还不够。因为指向int只能与a[0]的类型匹配,说明该指针指向一个int类型的值。但是 a是它首元素的地址,该元素是一个内含四个int类型值的一维数组。因此,b必须指向一个内含四个int类型值的数组,而不是指向一个int类型的值。 4.二维数组与函数 声明二维数组形参: void sum(int a[][len],int row)//len不能省略 或 void sum(int (*b)[len],int row)//len不能省略转载地址:http://liqwz.baihongyu.com/
你可能感兴趣的文章